우선순위 큐(Priority Queue)
1. 우선순위 큐란?

보통의 큐는 선입 선출(FIFO)의 원칙에 의하여 먼저 들어온 데이터가 먼저 나가게 된다.
그러나 우선순위 큐는 데이터들이 우선 순위를 가지고 있고 우선 순위가 높은 데이터가 먼저 나가게 된다.
우선순위 큐는 2가지로 구분할 수 있다. 최소 우선순위 큐는 가장 우선 순위가 낮은 요소를 먼저 삭제하고, 최대 우선순위 큐는 반대로 가장 우선 순위가 높은 요소가 먼저 삭제된다.
우선순위 큐는 대표적으로 시뮬레이션 시스템, 네트워크 트래픽 제어, 운영체제에서의 작업 스케쥬링, 수치 해석적인 계산 등 컴퓨터의 여러 분야에서 이용된다.
우선순위 큐는 배열, 연결 리스트, 힙으로 구현이 가능한데, 가장 효율적인 구조는 힙이다.
2. 우선순위 큐의 구현 방법

배열, 연결리스트, 힙으로 구현할 수 있는데 힙이 시간 복잡도가 가장 효율적이다.
삽입, 삭제 연산에서 최악의 경우 각각 루트 노드까지 올라가거나(삽입) 마지막 노드를 루트로 가져온 후 자식 노드들과 비교하며 가장 아래 레벨까지 내려가야 하므로(삭제) 트리의 높이(logn)만큼의 시간이 걸린다.
따라서 삽입, 삭제의 시간 복잡도는 O(logn)이다.
3. 힙
힙(Heap)은 우선순위 큐를 위해 고안된 완전이진트리 형태의 자료구조이다.
여러 개의 값 중 최댓값 또는 최솟값을 찾아내는 연산이 빠르다.
힙의 특징
- 완전이진트리 형태로 이루어져 있다.
- 부모노드와 자식 노드간 대소 관계가 성립된다.
- 느슨한 정렬 상태(큰 값이 상위 레벨, 작은 값이 하위 레벨)
- 이진탐색트리(BST)와 달리 중복된 값이 허용된다.
힙의 종류
- 최대 힙(Max Heap) : 부모 노드의 키 값이 자식 노드보다 크거나 같은 완전이진트리

- 최소 힙(Min Heap) : 부모 노드의 키 값이 자식 노드보다 작거나 같은 완전이진트리

힙의 구현
힙을 저장하는 표준적인 자료구조는 배열이다.
힙은 완전 이진 트리이기 때문에 각각의 노드에 차례대로 번호를 붙이고, 이 번호를 배열의 인덱스로 생각하면 배열에 히프의 노드들을 저장할 수 있다.
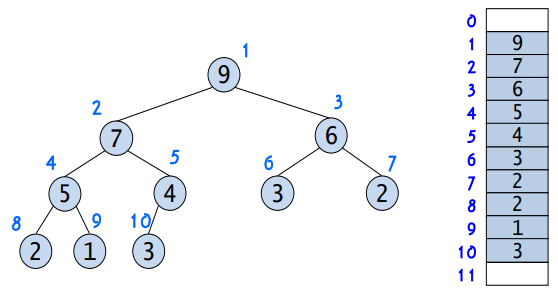
배열을 이용하여 힙을 저장하면 완전 이진 트리에서처럼 자식 노드와 부모 노드를 쉽게 알 수 있다.
- 왼쪽 자식의 인덱스 = (부모의 인덱스) * 2
- 오른쪽 자식의 인덱스 = (부모의 인덱스) * 2 + 1
- 부모의 인덱스 = (자식의 인덱스/2)
힙의 정의
#define MAX_ELEMENT 200
typedef struct { // 정수값 하나 구조체
int key;
}element;
typedef struct { // 힙과 힙사이즈를 담은 구조체
element heap[MAX_ELEMENT]; // 힙을 구현한 배열
int heap_size; // 힙 안에 저장된 요소의 개수
}HeapType;
c언어로 힙을 구현하였다.
힙의 요소를 구조체 element로 정의하고, element의 1차원 배열을 만들어 힙을 구현했다.
삽입 연산
1. 힙에 새로운 요소가 들어오면, 새로운 노드를 힙의 마지막 노드로 삽입한다.
2. 부모 노드와 비교하여 부모 노드보다 새로운 노드가 크다면 서로 교환한다.
3. 힙 속성이 유지될 때까지 2번 작업을 반복한다.

// 현재 요소의 개수가 heap_size인 히프 h에 item을 삽입
void insert_max_heap(HeapType *h, element item) {
int i = ++(h->heap_size); // 힙 끝에 새로운 노드 삽입
while ((i!=1) && item.key > h->heap[i / 2].key) { // 루트 노드가 아니고
// i번째 노드가 i의 부모 노드보다 크다면
h->heap[i] = h->heap[i / 2]; // 부모 노드가 내려옴
i = i / 2; // 한 레벨 위로 승진
}
h->heap[i]= item; // 새로운 노드를 삽입
}
삭제 연산
최대 힙에서 삭제 연산은 최대값을 가진 요소를 삭제하는 것이다.
1. 루트 노드가 삭제된다.
2. 빈 루트 노드 자리에 힙의 마지막 노드를 가져온다.
3. 새로운 루트 노드와 자식 노드를 비교해 자식 노드가 더 크면 교환이 일어난다. 이 때 자식 중에서 더 큰 값과 교환이 일 어난다.
4. 힙 속성이 유지될 때까지 3번 과정을 반복한다.

element delete_max_heap(HeapType* h) {
int parent, child;
element item, temp;
item = h->heap[1]; // 루트 노드 값 반환
temp = h->heap[(h->heap_size)--]; // 말단 노드 값 보관, 힙 사이즈 1 감소
parent = 1;
child = 2;
while (child <= h->heap_size) { // 자식 노드가 전체 데이터의 노드 수 보다 같거나 작을 때
// 현재 노드의 자식노드 중 더 큰 자식노드를 찾는다.
if ((child < h->heap_size) &&
(h->heap[child].key) < h->heap[child + 1].key)
child++;
if (temp.key >= h->heap[child].key) break;
// temp값이 루트 노드의 자식 노드보다 크지 않다면
h->heap[parent] = h->heap[child]; // 자식 노드 값을 부모 노드 값으로
// 한 단계 아래로 이동
parent = child;
child *= 2;
}
h->heap[parent] = temp; // 말단 노드 값을 부모 자리에 삽입
return item; // 최대값(루트값) 반환
}
힙 정렬
힙을 이용하면 정렬을 할 수 있다. n개의 요소는 O(nlogn) 시간 안에 정렬된다.
과정은 다음과 같다.
1. 정렬할 n개 원소로 최대 힙을 구성한다.
2. 최대 힙의 마지막 노드 값을 루트에 위치하고 루트 원소를 꺼내 배열에 저장한다.
3. 새 루트 노드에 대해 최대 힙을 구성한다.
4. 원소 개수만큼 2번과 3번 과정을 반복 수행한다.
과정 1은 힙의 삽입 과정으로 하나의 요소를 힙에 삽입할때 O(logn)이 걸리고, n개의 요소에 대해서 삽입해야 하므로 O(nlogn)만큼 소요된다.
과정 2와 3은 최대 힙에서 원소를 하나 삭제한 후 재구성하는 것이므로 O(logn)이 걸린다. 이 과정도 n개의 요소에 대해서 반복되므로 O(nlogn)의 시간이 걸린다.
따라서 힙 정렬은 O(nlogn) + O(nlogn) = O(nlogn)의 시간 복잡도를 가진다.
'CS > 자료구조' 카테고리의 다른 글
| [자료구조] 인접 행렬, 인접 리스트 시간 복잡도 코드 구현 (0) | 2022.10.25 |
|---|---|
| 자료구조와 알고리즘, 추상 데이터타입 개념 (0) | 2022.10.19 |
| [자료구조] 그래프(Graph) 개념, 구현 (0) | 2022.10.19 |
| [자료구조] 우선순위 큐를 이용한 머신 스케줄링 (0) | 2022.10.18 |